Projects
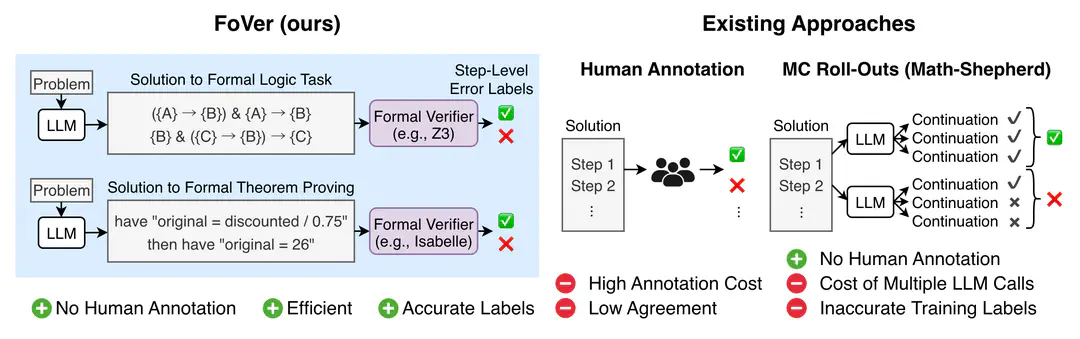
Process Reward Models (PRMs) provide step-level verification to LLM reasoning. However, PRM training data in prior work relies on human annotated labels or costly automatic methods, which generate noisy training labels. We propose FoVer, an efficient method to create accurate PRM training data from formal reasoning tasks using formal verification tools like Z3 and Isabelle. Experimental results demonstrate that FoVer improves PRM performance on widely used benchmarks for informal reasoning tasks.
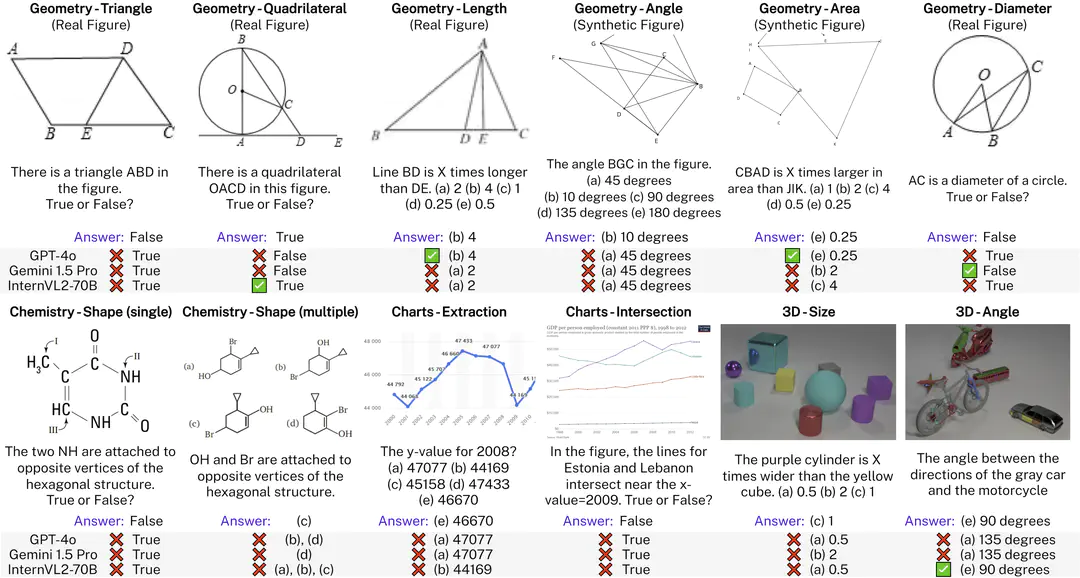
VisOnlyQA is a benchmark for evaluating the geometric perception capabilities of LVLMs, consisting of 12 tasks that ask about geometric properties (e.g., angle, size, and shape) in four categories of scientific figures: geometric shapes, charts, chemical structures, and 3D shapes. We demonstrate that LVLMs still often cannot accurately perceive basic geometric information in images.
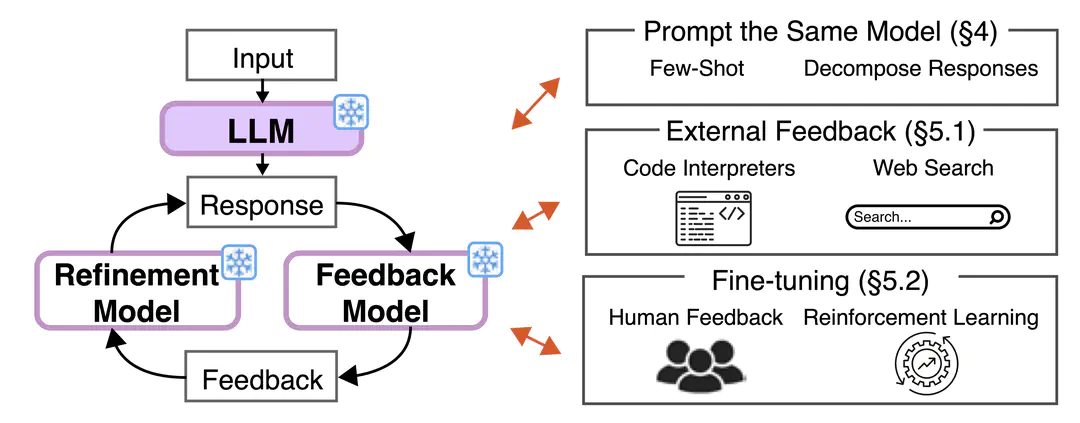
We critically survey broad papers and discuss the conditions required for successful self-correction. Our survey indicates that (1) no prior work demonstrates successful self-correction with feedback from prompted LLMs, except for studies in tasks that are exceptionally suited for self-correction, (2) self-correction works well in tasks that can use reliable external feedback, and (3) large-scale fine-tuning enables self-correction.
ReaLMistake is a benchmark for evaluating error detection methods that detects errors in LLM responses. This benchmark includes errors made by GPT-4 and Llama 2 70B on three tasks (math word problem generation, fine-grained fact verification, and answerability classification). We observe that LLMs still cannot reliably detect mistakes made by LLMs. Strong LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans.
